ガチなシャツ
リライブシャツすごすぎワロタwwwwww【リライブシャツを買ってみたらガチだった。】 リライブシャツ 着るだけで「身体機能をサポートする」怪しいシャツがガチだった。 YouTubeやSNSでバズってた「リライブ...

2021年12月に新しく追加されたアクションです。エンティティとは情報処理の自然言語処理分野の用語で固有表現のことを指しています。
固有表現とは、人名や地名などといった固有名詞や、日付表現、時間表現などに関する総称である。自然言語処理において、文書の中から固有表現を抽出する研究課題は固有表現抽出と呼ばれる。
引用:weblog辞書
「エンティティをテキストで認識する」アクションは上の引用文でいうところの固有表現抽出を行うアクションです。固有表現は自分でパターンを作成するのではなく、事前にパターンが定義されたものから選んで利用することができます。「エンティティをテキストで認識する」アクションでは事前定義済み固有表現を「エンティティの種類」と呼びます。
 じょじお
じょじお現在利用可能な「エンティティの種類」には下記があります。
 ぽこがみさま
ぽこがみさまこれらをテキストから抽出できるんですね!
エンティティの種類
じょじおここからは「エンティティをテキストで認識する」アクションの使用例をいくつか紹介したいと思います。
じょじおhtmlからURLを抽出してみます。
ここではスクレイピングの処理は省略します。下記の記事でスクレイピングのフローの紹介をしているのでご参考になさってください。


今回はスクレピングの代わりにテスト用に作成したWebページのhtmlの一部(下記)を用意しました。このhtmlを直接「エンティティをテキストで認識する」アクションに渡してみたいと思います。
<div class="flex">
<div class="sidebar">
<p>sidebar</p>
<li class="left-list">menu1</li>
<li class="left-list">menu2</li>
<li class="left-list">menu3</li>
</div><!-- sidebar -->
<div class="main-content">
<p>main contents</p>
<div class="section0">
<p>meat</p>
<li class="section2-list"><a href="https://www.google.com/search?q=carrot" target="_blank">pork</a></li>
<li class="section2-list"><a href="https://www.google.com/search?q=onion" target="_blank">beef</a></li>
<li class="section2-list"><a href="https://www.google.com/search?q=radish" target="_blank">chicken</a></li>
</div><!-- section2 -->
<div class="section1">
<p>fruits</p>
<li class="section1-list"><a href="https://www.google.com/search?q=apple" id="f-list1" target="_blank">apple</a></li>
<li class="section1-list"><a href="https://www.google.com/search?q=orange" id="f-list2" target="_blank">orange</a></li>
<li class="section1-list"><a href="https://www.google.com/search?q=melon" id="f-list3" target="_blank">melon</a></li>
</div><!-- section1 -->
<div class="section2">
<p>vegetable</p>
<li class="section2-list"><a href="https://www.google.com/search?q=carrot" target="_blank">carrot</a></li>
<li class="section2-list"><a href="https://www.google.com/search?q=onion" target="_blank">onion</a></li>
<li class="section2-list"><a href="https://www.google.com/search?q=radish" target="_blank">radish</a></li>
</div><!-- section2 -->
</div><!-- main-content -->
</div><!-- flex -->
▲<li class= …のところにURLが9つ含んでいることがわかるかと思います。URL部分だけを抽出できるかやってみたいと思います。
▲「テキスト」グループの中の「エンティティをテキストで認識する」を追加します。
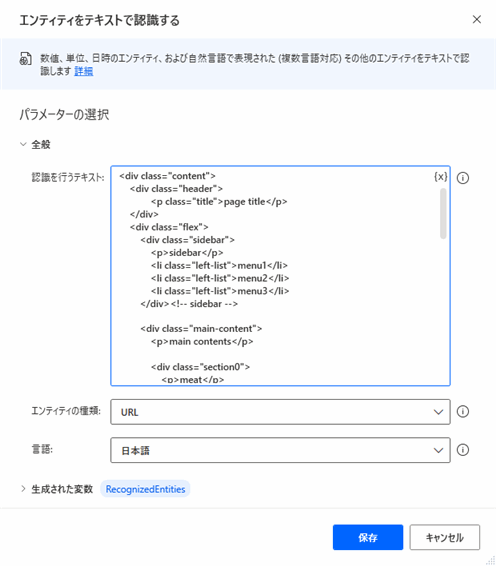
▲パラメータを入力します。
フローを実行して結果を確認します。実行結果は%RecognizedEntities%変数に格納されます。%RecognizedEntities%をダブルクリックして中身を見てみましょう。
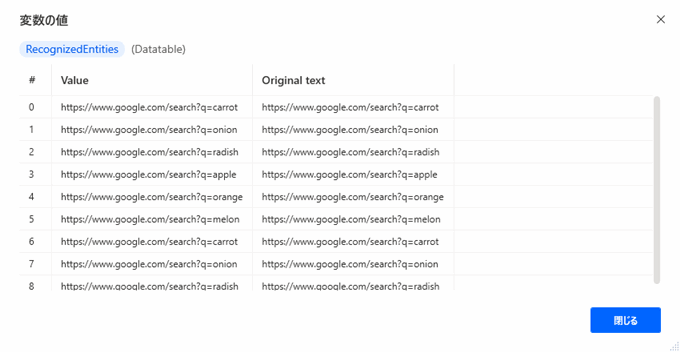
▲htmlの中に記述されていた9つのURLをすべて抽出することができました。
Text.RecognizeEntitiesInText Text: $'''<div class=\"content\">
<div class=\"header\">
<p class=\"title\">page title</p>
</div>
<div class=\"flex\">
<div class=\"sidebar\">
<p>sidebar</p>
<li class=\"left-list\">menu1</li>
<li class=\"left-list\">menu2</li>
<li class=\"left-list\">menu3</li>
</div><!-- sidebar -->
<div class=\"main-content\">
<p>main contents</p>
<div class=\"section0\">
<p>meat</p>
<li class=\"section2-list\"><a href=\"https://www.google.com/search?q=carrot\" target=\"_blank\">pork</a></li>
<li class=\"section2-list\"><a href=\"https://www.google.com/search?q=onion\" target=\"_blank\">beef</a></li>
<li class=\"section2-list\"><a href=\"https://www.google.com/search?q=radish\" target=\"_blank\">chicken</a></li>
</div><!-- section2 -->
<div class=\"section1\">
<p>fruits</p>
<li class=\"section1-list\"><a href=\"https://www.google.com/search?q=apple\" id=\"f-list1\" target=\"_blank\">apple</a></li>
<li class=\"section1-list\"><a href=\"https://www.google.com/search?q=orange\" id=\"f-list2\" target=\"_blank\">orange</a></li>
<li class=\"section1-list\"><a href=\"https://www.google.com/search?q=melon\" id=\"f-list3\" target=\"_blank\">melon</a></li>
</div><!-- section1 -->
<div class=\"section2\">
<p>vegetable</p>
<li class=\"section2-list\"><a href=\"https://www.google.com/search?q=carrot\" target=\"_blank\">carrot</a></li>
<li class=\"section2-list\"><a href=\"https://www.google.com/search?q=onion\" target=\"_blank\">onion</a></li>
<li class=\"section2-list\"><a href=\"https://www.google.com/search?q=radish\" target=\"_blank\">radish</a></li>
</div><!-- section2 -->
</div><!-- main-content -->
</div><!-- flex -->
<div class=\"footer\">
<p>footer section</p>
</div><!-- footer -->
</div><!-- content -->''' Mode: Text.RecognizerMode.Url Language: Text.RecognizerLanguage.Japanese RecognizedEntities=> RecognizedEntities
▲フローデザイナーに張り付けることでここで作成したフローをご自分のPCで再現することができます。
じょじお見積メール・発注メールなどから金額だけを抽出します。
本来は「Outlook」グループのアクションを使って受信メールを取得するところからフローをつくるべきですが今回はテストのため省略します。
下記のメール文をそのまま「エンティティをテキストで認識する」アクションに貼り付けます。
平素よりお引き立てを賜り、感謝いたしております。 株式会社てじらぼのじょじおです。 さて、〇〇代金の詳細についてのお問い合わせ、ありがとうございます。 今回ご案内いたしました〇〇の詳細は、以下の通りですのでご確認ください。 航空券代 59,800円 宿泊代 30,000円 (2泊分) 食事代 5,000円 (朝食2回 ホテルのレストランにて) 合計 94,800円(税込み) ご質問などございましたら、ご遠慮なくお問い合わせください。 ------------------------------------------------------ 株式会社 てじらぼ じょじお 〒123-4567 東京都○○市△△町11-22 ◇◇ビル3F TEL:03-9999-9999(直通) 03-9999-9999 (代表) Mobile:070-1234-5678 FAX:03-9999-9999 ------------------------------------------------------
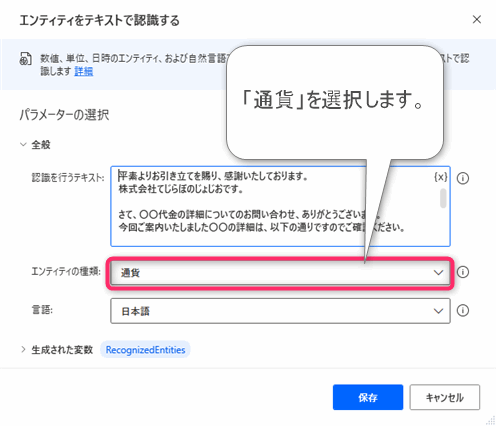
▲金額を抽出するときはエンティティの種類は「通貨」にします。
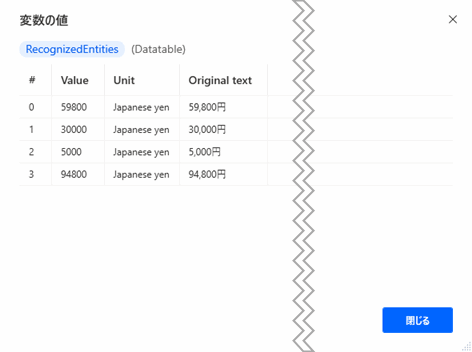
▲金額を抽出することができました。通貨の場合、Unit(通貨情報)も取得することができます。日本円はJapanese Yenです。(たまに日本円をChinese Yenとして認識することがあったりするので注意してください)
Text.RecognizeEntitiesInText Text: $'''平素よりお引き立てを賜り、感謝いたしております。 株式会社てじらぼのじょじおです。 さて、〇〇代金の詳細についてのお問い合わせ、ありがとうございます。 今回ご案内いたしました〇〇の詳細は、以下の通りですのでご確認ください。 航空券代 59,800円 宿泊代 30,000円 (2泊分) 食事代 5,000円 (朝食2回 ホテルのレストランにて) 合計 94,800円(税込み) ご質問などございましたら、ご遠慮なくお問い合わせください。 ------------------------------------------------------ 株式会社 てじらぼ じょじお 〒123-4567 東京都○○市△△町11-22 ◇◇ビル3F TEL:03-9999-9999(直通) 03-9999-9999 (代表) Mobile:070-1234-5678 FAX:03-9999-9999 ------------------------------------------------------ ''' Mode: Text.RecognizerMode.Currency Language: Text.RecognizerLanguage.Japanese RecognizedEntities=> RecognizedEntities
じょじおツイッターのハッシュタグを抽出してみます。
▲今回こちらのわたしの過去ツイートの文章をターゲットにしました。このツイート文章から文章に含まれる4つのハッシュタグを取り出してみたいと思います。
▲「エンティティをテキストで認識する」アクションは、テキストグループの中にあります。
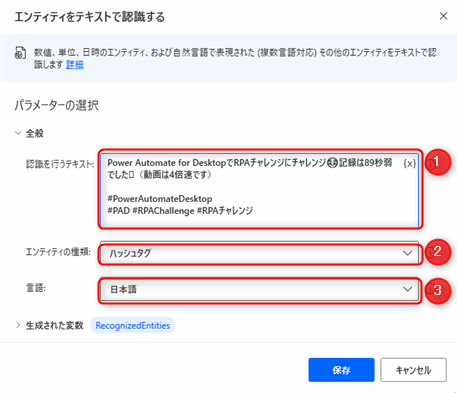
▲「エンティティをテキストで認識する」アクションのパラメータを入力します。
フローを実行します。「エンティティをテキストで認識する」アクションはデフォルトではRecognizedEntitiesというDatatable型の変数に結果を出力します。
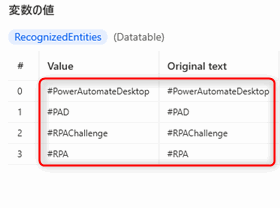
RecognizedEntities変数を確認してみるとツイート文に含まれた4つのハッシュタグを全て抽出してくれていました。
「エンティティをテキストで認識する」アクションは実行結果を%RecognizedEntities%変数に格納します。%RecognizedEntities%変数はDatatable型の変数です。
Excel表を読み込んだ時に生成されるExcelData変数と同じですね。プログラム的な言葉でいうと2次元配列です。Datatable型変数をループ処理したり加工したりする方法については下記の記事でまとめていますのでご参考になさってください。



下記の記事では、もう少し具体的で実践的な「エンティティをテキストで認識する」アクションの使用例として、Uber Eatsの領収書メールを1か月分Outlookからまるっと取得して、1か月の合計金額を算出する方法について紹介しています。
>(記事準備中)
じょじお従来このようにハッシュタグなどのパターン抽出を行う場合、正規表現を使ってパターンを表現する必要があったので、正規表現の知識を持たないノンプログラマーにとってはありがたいアクションかなぁと思います!
ぽこがみさま今後「エンティティの種類」がもっと増えていくとより出番の多いアクションになりそうです!
じょじお「エンティティの種類」に存在しないパターン(郵便番号など)でテキスト抽出を行う方法については下記の記事で解説しています。宜しかったらご参考になさってください!
 じょじお
じょじおこの記事では「エンティティをテキストで認識する」を使ってテキストから特定のパターンの文字列を抽出する方法について紹介しました。
ぽこがみさまこのブログではRPA・ノーコードツール・VBA/GAS/Pythonを使った業務効率化などについて発信しています。
参考になりましたらブックマーク登録お願いします!

▲Kindleと紙媒体両方提供されています。デスクトップフロー、クラウドフロー両方の解説がある書籍です。解説の割合としてはデスクトップフロー7割・クラウドフロー3割程度の比率となっています。両者の概要をざっくり理解するのにオススメです。

▲Power Automate for Desktopの基本をしっかり学習するのにオススメです。この本の一番のメリットはデモWebシステム・デモ業務アプリを実際に使ってハンズオン形式で学習できる点です。本と同じシステム・アプリを使って学習できるので、本と自分の環境の違いによる「よく分からないエラー」で無駄に躓いて挫折してしまう可能性が低いです。この点でPower Automate for desktopの一冊目のテキストとしてオススメします。著者は日本屈指のRPAエンジニア集団である『ロボ研』さんです。

▲Power Automate クラウドフローの入門書です。初心者の方には図解も多く一番わかりやすいかと個人的に思っています。
Microsoft 365/ Power Automate / Power Platform / Google Apps Script…
▲Udemyで数少ないPower Automateクラウドフローを主題にした講座です。セール時は90%OFF(1200円~2000円弱)の価格になります。頻繁にセールを実施しているので絶対にセール時に購入してくださいね。満足がいかなければ返金保証制度がありますので安心してご購入いただけます。

