この記事でわかること!
Google Colabから環境構築なしでPythonでスプレッドシートを操作する方法がわかる。 スプレッドシートを操作するためのgspreadライブラリの基本的な使い方がわかる。 Google Colaboratoryでスプレッドシートを操作する方法。
Google Colaboratoryからスプレッドシートに書き込むにはgspreadライブラリを使う方法が最も一般的です。Google Colaboratoryにはgspreadがあらかじめインストールされているので基本的にはpip installコマンドを実行してインストールする必要はありません。
Google Colabとは?
Pythonの実行環境を爆速で用意できるGoogle Colabを使い方解説!
この記事でわかること! Pythonの実行環境を最速で用意できるGoogle colaboratoryのメリットがわかる。Pythonの実行環境を最速で用意できるGoogle colaboratoryの初期設…
認証を行う方法
じょじお
gspreadを使うためにはGoogle Colaboratoryの認証 を行う必要があります。
他の人のGoogle Colaboratoryから自分のスプレッドシートにむやみやたらにアクセスされてしまったら困ってしまいますよね。そういったことができないようにスプレッドシートへのプログラムからの書き込みには認証が必要になっています。
Google Colaboratoryから認証を行う方法は、この後に紹介するコードを実行することです。
コード実行後にGoogleアカウント情報の入力を求められるので入力を行います。これによって「このGoogle Colaboratoryからのスプレッドシートへの書き込みは信頼されてます。」ということを証明しスプレッドシートの操作を開始することができます。
STEP
認証用コードを実行します。
from google.colab import auth
from google.auth import default
gc = gspread. authorize ( creds )
# 認証のためのコード
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
gc = gspread.authorize(creds)
# 認証のためのコード
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
gc = gspread.authorize(creds)
▲コードをコピペして実行します。お決まりのコードなので深く考えずにコピペして実行しても大丈夫です。
STEP
許可するかどうかを問われるので「Allow(許可)」をクリックします。
▲認証用のコードを実行すると図のメッセージがGoogle Colaboratory上に表示されますので「Allow(許可)」をクリックします。
Allow this notebook to access your Google credentials?
STEP
Google認証情報の入力を求められるのでIDとPWを入力します。
▲Googleの認証情報の入力を求められるので入力します。
STEP
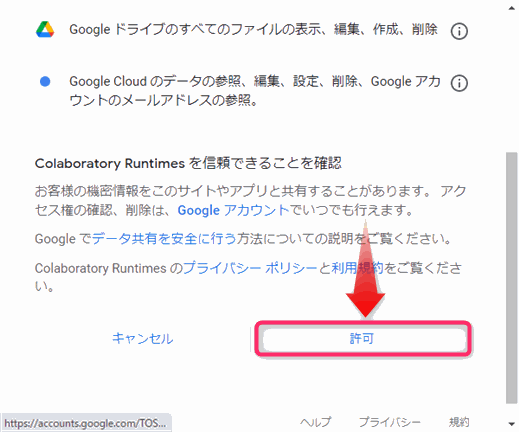
Googleサービスへのアクセス権を許可します。
▲図の画面が表示されるので「許可 」をクリックします。
STEP
認証完了です。
ぽこがみさま
スプレッドシートファイルの操作(ブックの操作)
スプレッドシートファイルを開く(ファイル名から)
filename = "my cool spreadsheet"
## スプレッドシートを開く(名前から)
filename = "my cool spreadsheet"
ss = gc.open(filename)
## スプレッドシートを開く(名前から)
filename = "my cool spreadsheet"
ss = gc.open(filename)
スプレッドシートファイルを開く(URLから)
url = "https://docs.google.com/spreadsheets/d/1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc/"
## スプレッドシートを開く(シートURLから)
url = "https://docs.google.com/spreadsheets/d/1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc/"
ss = gc.open_by_url(url)
## スプレッドシートを開く(シートURLから)
url = "https://docs.google.com/spreadsheets/d/1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc/"
ss = gc.open_by_url(url)
スプレッドシートファイルを開く(IDから)
# ss_key = '1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc'
# ss = gc.open_by_key(ss_key)
## スプレッドシートを開く(シートIDから)
# ss_key = '1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc'
# ss = gc.open_by_key(ss_key)
## スプレッドシートを開く(シートIDから)
# ss_key = '1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc'
# ss = gc.open_by_key(ss_key)
スプレッドシートファイルの新規作成
filename = "my new spreadsheet"
## スプレッドシートの作成
filename = "my new spreadsheet"
ss = gc.create(filename)
print(ss.title)
# 実行結果
>>> my new spreadsheet
## スプレッドシートの作成
filename = "my new spreadsheet"
ss = gc.create(filename)
print(ss.title)
# 実行結果
>>> my new spreadsheet
スプレッドシートIDを取得する。
>>> 1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc
## スプレッドシートIDを取得する。
print(ss.id)
# 実行結果
>>> 1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc
## スプレッドシートIDを取得する。
print(ss.id)
# 実行結果
>>> 1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc
スプレッドシートのURLを取得する。
>>> https://docs.google.com/spreadsheets/d/1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc/
## スプレッドシートのURLを取得する。
print(ss.url)
# 実行結果
>>> https://docs.google.com/spreadsheets/d/1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc/
## スプレッドシートのURLを取得する。
print(ss.url)
# 実行結果
>>> https://docs.google.com/spreadsheets/d/1XEUahcTD8bpfs-fhxATmnUiCXKxrtMWXCWwvNe3Iosc/
スプレッドシート名を取得する。
## スプレッドシートの名前を取得する。
print(ss.title)
# 実行結果
>>> my new spreadsheet
## スプレッドシートの名前を取得する。
print(ss.title)
# 実行結果
>>> my new spreadsheet
シートの操作
シートを特定する(シートインデックスから)
st = ss. get_worksheet ( 0 ) #0は左から1番目のシート
# シートを特定する(シートインデックスで特定)
st = ss.get_worksheet(0) #0は左から1番目のシート
# シートを特定する(シートインデックスで特定)
st = ss.get_worksheet(0) #0は左から1番目のシート
シートを特定する(シート名から)
st = ss. worksheet ( "シート1" )
# シートを特定する(シート名で特定)
st = ss.worksheet("シート1")
# シートを特定する(シート名で特定)
st = ss.worksheet("シート1")
すべてのシートを取得する
worksheet_list = ss. worksheets ()
>>> [< Worksheet 'シート2' id: 895989010 > , < Worksheet 'シート3' id: 1630761420 > , < Worksheet 'シート4' id: 132226181 > , < Worksheet 'renamed-st' id: 866995743 > , < Worksheet 'StB' id: 1807717637 >]
## すべてのシートをリストで取得する。
worksheet_list = ss.worksheets()
print(worksheet_list)
# 実行結果
>>> [<Worksheet 'シート2' id:895989010>, <Worksheet 'シート3' id:1630761420>, <Worksheet 'シート4' id:132226181>, <Worksheet 'renamed-st' id:866995743>, <Worksheet 'StB' id:1807717637>]
## すべてのシートをリストで取得する。
worksheet_list = ss.worksheets()
print(worksheet_list)
# 実行結果
>>> [<Worksheet 'シート2' id:895989010>, <Worksheet 'シート3' id:1630761420>, <Worksheet 'シート4' id:132226181>, <Worksheet 'renamed-st' id:866995743>, <Worksheet 'StB' id:1807717637>]
すべてのシートをループで操作する。
worksheet_list = ss. worksheets ()
worksheet_list = ss.worksheets()
for s in worksheet_list:
print(s.title)
# 実行結果
>>> シート2
>>> シート3
>>> シート4
>>> renamed-st
>>> StB
worksheet_list = ss.worksheets()
for s in worksheet_list:
print(s.title)
# 実行結果
>>> シート2
>>> シート3
>>> シート4
>>> renamed-st
>>> StB
シートを新しく挿入する。
シートを挿入するときはadd_worksheet を使います。シート名、行数、列数の指定も必須です。同じシート名のシートがすでに存在する場合エラーになります。
st2 = ss. add_worksheet ( title=st_name, rows= 30 , cols= 20 )
# シートを新しく挿入する。
st_name = "StB"
try:
st2 = ss.add_worksheet(title=st_name, rows=30, cols=20)
except Exception as e:
print(e)
# シートを新しく挿入する。
st_name = "StB"
try:
st2 = ss.add_worksheet(title=st_name, rows=30, cols=20)
except Exception as e:
print(e)
シートを削除する。
シートを削除するにはスプレッドシートオブジェクトのdel_worksheet(シートオブジェクト) を使います。シートが存在しない場合やスプレッドシート内にシートが1枚しかない場合はエラーになります。
# シートを削除する。
try:
ss.del_worksheet(st)
except Exception as e:
print(e)
# シートを削除する。
try:
ss.del_worksheet(st)
except Exception as e:
print(e)
シート名を取得する。
# シート名を取得する。
print(st.title)
# シート名を取得する。
print(st.title)
シート名を変更する。
シート名を変更する場合は、シートオブジェクトのupdate_title(“変更後シート名”)を使います。
# シート名の変更
st_name = "StB"
try:
st.update_title(st_name)
except Exception as e:
print(e)
# シート名の変更
st_name = "StB"
try:
st.update_title(st_name)
except Exception as e:
print(e)
セル・セル範囲の操作
すべてのデータを取得する。(リストとして読み込み)
すべてのデータをリストとして読み込みます。1行が1リストに格納され、さらにすべての行がリストに格納されるので2次元配列として読み込まれます。
st = ss. worksheet ( "シート1" )
list_of_lists = st. get_all_values ()
>>> [[ 'id' , 'name' , 'name_kana' , 'sex' , 'tel_number' , 'birthday' ] , [ '1' , '松野将文' , 'マツノマサフミ' , '男' , '956019558' , '1973/09/10' ] , [ '2' , '梅津広行' , 'ウメヅヒロユキ' , '男' , '986297776' , '1982/08/26' ] , [ '3' , '佐伯勇人' , 'サエキハヤト' , '男' , '768613991' , '1984/06/29' ] , [ '4' , '平賀忠夫' , 'ヒラガタダオ' , '男' , '748304634' , '2001/02/28' ]]
# データを取得する。(リストとして)
st = ss.worksheet("シート1")
list_of_lists = st.get_all_values()
print(list_of_lists)
# 実行結果
>>> [['id', 'name', 'name_kana', 'sex', 'tel_number', 'birthday'], ['1', '松野将文', 'マツノマサフミ', '男', '956019558', '1973/09/10'], ['2', '梅津広行', 'ウメヅヒロユキ', '男', '986297776', '1982/08/26'], ['3', '佐伯勇人', 'サエキハヤト', '男', '768613991', '1984/06/29'], ['4', '平賀忠夫', 'ヒラガタダオ', '男', '748304634', '2001/02/28']]
# データを取得する。(リストとして)
st = ss.worksheet("シート1")
list_of_lists = st.get_all_values()
print(list_of_lists)
# 実行結果
>>> [['id', 'name', 'name_kana', 'sex', 'tel_number', 'birthday'], ['1', '松野将文', 'マツノマサフミ', '男', '956019558', '1973/09/10'], ['2', '梅津広行', 'ウメヅヒロユキ', '男', '986297776', '1982/08/26'], ['3', '佐伯勇人', 'サエキハヤト', '男', '768613991', '1984/06/29'], ['4', '平賀忠夫', 'ヒラガタダオ', '男', '748304634', '2001/02/28']]
すべてのデータを取得する。(辞書として読み込み)
すべてのデータを辞書として読み込みます。取り扱うスプレッドシートの1行目にヘッダー(列見出し)があるときはget_all_records()で辞書として読み込むこともできます。
st = ss. worksheet ( "シート1" )
list_of_dicts = st. get_all_records ()
>>> [{ 'id' : 1 , 'name' : '松野将文' , 'name_kana' : 'マツノマサフミ' , 'sex' : '男' , 'tel_number' : 956019558 , 'birthday' : '1973/09/10' } , { 'id' : 2 , 'name' : '梅津広行' , 'name_kana' : 'ウメヅヒロユキ' , 'sex' : '男' , 'tel_number' : 986297776 , 'birthday' : '1982/08/26' } , { 'id' : 3 , 'name' : '佐伯勇人' , 'name_kana' : 'サエキハヤト' , 'sex' : '男' , 'tel_number' : 768613991 , 'birthday' : '1984/06/29' } , { 'id' : 4 , 'name' : '平賀忠夫' , 'name_kana' : 'ヒラガタダオ' , 'sex' : '男' , 'tel_number' : 748304634 , 'birthday' : '2001/02/28' }]
# データを取得する(辞書として)
st = ss.worksheet("シート1")
list_of_dicts = st.get_all_records()
print(list_of_dicts)
# 実行結果
>>> [{'id': 1, 'name': '松野将文', 'name_kana': 'マツノマサフミ', 'sex': '男', 'tel_number': 956019558, 'birthday': '1973/09/10'}, {'id': 2, 'name': '梅津広行', 'name_kana': 'ウメヅヒロユキ', 'sex': '男', 'tel_number': 986297776, 'birthday': '1982/08/26'}, {'id': 3, 'name': '佐伯勇人', 'name_kana': 'サエキハヤト', 'sex': '男', 'tel_number': 768613991, 'birthday': '1984/06/29'}, {'id': 4, 'name': '平賀忠夫', 'name_kana': 'ヒラガタダオ', 'sex': '男', 'tel_number': 748304634, 'birthday': '2001/02/28'}]
# データを取得する(辞書として)
st = ss.worksheet("シート1")
list_of_dicts = st.get_all_records()
print(list_of_dicts)
# 実行結果
>>> [{'id': 1, 'name': '松野将文', 'name_kana': 'マツノマサフミ', 'sex': '男', 'tel_number': 956019558, 'birthday': '1973/09/10'}, {'id': 2, 'name': '梅津広行', 'name_kana': 'ウメヅヒロユキ', 'sex': '男', 'tel_number': 986297776, 'birthday': '1982/08/26'}, {'id': 3, 'name': '佐伯勇人', 'name_kana': 'サエキハヤト', 'sex': '男', 'tel_number': 768613991, 'birthday': '1984/06/29'}, {'id': 4, 'name': '平賀忠夫', 'name_kana': 'ヒラガタダオ', 'sex': '男', 'tel_number': 748304634, 'birthday': '2001/02/28'}]
>>> { 'id' : 1 , 'name' : '松野将文' , 'name_kana' : 'マツノマサフミ' , 'sex' : '男' , 'tel_number' : 956019558 , 'birthday' : '1973/09/10' }
>>> { 'id' : 2 , 'name' : '梅津広行' , 'name_kana' : 'ウメヅヒロユキ' , 'sex' : '男' , 'tel_number' : 986297776 , 'birthday' : '1982/08/26' }
>>> { 'id' : 3 , 'name' : '佐伯勇人' , 'name_kana' : 'サエキハヤト' , 'sex' : '男' , 'tel_number' : 768613991 , 'birthday' : '1984/06/29' }
>>> { 'id' : 4 , 'name' : '平賀忠夫' , 'name_kana' : 'ヒラガタダオ' , 'sex' : '男' , 'tel_number' : 748304634 , 'birthday' : '2001/02/28' }
# ループで1行ずつ取り出す。
for r in list_of_dicts:
print(r)
# 実行結果
>>> {'id': 1, 'name': '松野将文', 'name_kana': 'マツノマサフミ', 'sex': '男', 'tel_number': 956019558, 'birthday': '1973/09/10'}
>>> {'id': 2, 'name': '梅津広行', 'name_kana': 'ウメヅヒロユキ', 'sex': '男', 'tel_number': 986297776, 'birthday': '1982/08/26'}
>>> {'id': 3, 'name': '佐伯勇人', 'name_kana': 'サエキハヤト', 'sex': '男', 'tel_number': 768613991, 'birthday': '1984/06/29'}
>>> {'id': 4, 'name': '平賀忠夫', 'name_kana': 'ヒラガタダオ', 'sex': '男', 'tel_number': 748304634, 'birthday': '2001/02/28'}
# ループで1行ずつ取り出す。
for r in list_of_dicts:
print(r)
# 実行結果
>>> {'id': 1, 'name': '松野将文', 'name_kana': 'マツノマサフミ', 'sex': '男', 'tel_number': 956019558, 'birthday': '1973/09/10'}
>>> {'id': 2, 'name': '梅津広行', 'name_kana': 'ウメヅヒロユキ', 'sex': '男', 'tel_number': 986297776, 'birthday': '1982/08/26'}
>>> {'id': 3, 'name': '佐伯勇人', 'name_kana': 'サエキハヤト', 'sex': '男', 'tel_number': 768613991, 'birthday': '1984/06/29'}
>>> {'id': 4, 'name': '平賀忠夫', 'name_kana': 'ヒラガタダオ', 'sex': '男', 'tel_number': 748304634, 'birthday': '2001/02/28'}
# ループで1行ずつ、name列だけ取り出す
for r in list_of_dicts:
print(r["name"])
# 実行結果
>>> 松野将文
>>> 梅津広行
>>> 佐伯勇人
>>> 平賀忠夫
# ループで1行ずつ、name列だけ取り出す
for r in list_of_dicts:
print(r["name"])
# 実行結果
>>> 松野将文
>>> 梅津広行
>>> 佐伯勇人
>>> 平賀忠夫
単一セルに書き込む(行列番号の指定)
単一セルに書き込みます。行番号と列番号をインデックスで指定します。
st = ss. worksheet ( "シート1" )
st. update_cell ( 8 , 1 , "1000000" ) #8行目1列目
# セルに入力
st = ss.worksheet("シート1")
st.update_cell(8 ,1, "1000000") #8行目1列目
# セルに入力
st = ss.worksheet("シート1")
st.update_cell(8 ,1, "1000000") #8行目1列目
単一セルに書き込む(A1形式の指定)
単一セルに書き込みます。セルのアドレスはA1ノーテーションの形式で文字列で指定します。
st = ss. worksheet ( "シート1" )
st. update_acell ( "A9" , "20000000" )
# セルに入力
st = ss.worksheet("シート1")
st.update_acell("A9", "20000000")
# セルに入力
st = ss.worksheet("シート1")
st.update_acell("A9", "20000000")
複数セルに書き込む(update_cell)
複数セルに書き込むにはupdate_cellsを使うことができます。ただし、ループの中で多くのAPIコールが発生します。データが多い場合はAPIコール上限の規制に引っかかる可能性が高いので、この後に紹介する別の方法も検討してください。cell.valueに格納したあとにupdate_cell関数を実行しないと書き込みは確定されません。
cell_list = st. range ( 'A10:C17' )
st. update_cells ( cell_list )
# セルに入力(複数行)
cell_list = st.range('A10:C17')
for cell in cell_list:
cell.value = 'テストバリュー'
# 下記のコマンドで確定します。
st.update_cells(cell_list)
# セルに入力(複数行)
cell_list = st.range('A10:C17')
for cell in cell_list:
cell.value = 'テストバリュー'
# 下記のコマンドで確定します。
st.update_cells(cell_list)
リストを一括で書き込む
リストを一括で書き込むにはスプレッドシートオブジェクトのvalues_appendが有効な手段です。既存データの最終行にリストをアペンド(追記)します。一撃で書き込めるのでAPIコール数を節約できます。
data1 = [[ '1' , '2' , '3' ] , [ '10' , '11' , '12' ] , [ '20' , '21' , '22' ]]
ss. values_append ( "シート1" , { "valueInputOption" : "USER_ENTERED" } , { "values" : data1 })
# 単一リストの場合も下記のように[]で囲み2次元リストにしないとエラーになります。
data2 = [[ '300' , '301' , '302' ]]
ss. values_append ( "シート1" , { "valueInputOption" : "USER_ENTERED" } , { "values" : data2 })
# 2次元配列を一括で書き込み
data1 = [['1', '2', '3'], ['10', '11', '12'], ['20', '21', '22']]
ss.values_append("シート1", {"valueInputOption": "USER_ENTERED"}, {"values": data1})
# 単一リストの場合も下記のように[]で囲み2次元リストにしないとエラーになります。
data2 = [['300', '301', '302']]
ss.values_append("シート1", {"valueInputOption": "USER_ENTERED"}, {"values": data2})
# 2次元配列を一括で書き込み
data1 = [['1', '2', '3'], ['10', '11', '12'], ['20', '21', '22']]
ss.values_append("シート1", {"valueInputOption": "USER_ENTERED"}, {"values": data1})
# 単一リストの場合も下記のように[]で囲み2次元リストにしないとエラーになります。
data2 = [['300', '301', '302']]
ss.values_append("シート1", {"valueInputOption": "USER_ENTERED"}, {"values": data2})
最終行と最終列番号を取得する。
get_all_valuesの1次元目と2次元目の要素数をlen関数で調べることで最終行番号と最終列番号がわかります。
list_of_lists = st. get_all_values ()
print ( len ( list_of_lists ))
list_of_lists = st. get_all_values ()
print ( len ( list_of_lists [ 0 ]))
# 最終行の取得
st = ss.get_worksheet(1)
list_of_lists = st.get_all_values()
print(len(list_of_lists))
# 最終行の取得
st = ss.get_worksheet(1)
list_of_lists = st.get_all_values()
print(len(list_of_lists[0]))
# 最終行の取得
st = ss.get_worksheet(1)
list_of_lists = st.get_all_values()
print(len(list_of_lists))
# 最終行の取得
st = ss.get_worksheet(1)
list_of_lists = st.get_all_values()
print(len(list_of_lists[0]))
すべてのセルの値を削除する。
シートのデータを一括でリフレッシュ(クリア)するにはclear()が便利です。
# シート内のデータを一括削除
st = ss.get_worksheet(1)
st.clear()
# シート内のデータを一括削除
st = ss.get_worksheet(1)
st.clear()
値からセルのアドレスを検索する。
PandasのDataFrameとスプレッドシートの連携
スプレッドシートのデータをPandasのデータフレームで扱うことも簡単です。データフレームをスプレッドシートに書き込むときはリストに変換します。スプレッドシートのデータをデータフレームにするにはリストにしてからデータフレームにします。
リストをPandasのDataFrameに変換
# スプレッドシートのデータをPandasのDataframeに変換する。
rows = st. get_all_values ()
df = pd.DataFrame. from_records ( rows )
# スプレッドシートのデータをPandasのDataframeに変換する。
rows = st.get_all_values()
import pandas as pd
df = pd.DataFrame.from_records(rows)
# スプレッドシートのデータをPandasのDataframeに変換する。
rows = st.get_all_values()
import pandas as pd
df = pd.DataFrame.from_records(rows)
PandasのDataFrameにリストを変換
values.tolist()でリストに変換します。update()でデータフレームのヘッダをシートの最初の行に入れ、その後にデータフレームの値を入れています。
# PandasのDataframeをリストに変換してスプレッドシートに書き出す。
list_from_df = df. to_numpy () . tolist ()
worksheet. update ([ df.columns.values. tolist ()] + df.values. tolist ())
# PandasのDataframeをリストに変換してスプレッドシートに書き出す。
list_from_df = df.to_numpy().tolist()
worksheet.update([df.columns.values.tolist()] + df.values.tolist())
# PandasのDataframeをリストに変換してスプレッドシートに書き出す。
list_from_df = df.to_numpy().tolist()
worksheet.update([df.columns.values.tolist()] + df.values.tolist())
Pandasの使い方
あわせて読みたい
【機械学習】Python Pandas データ前処理について初心者向けに解説します。
この記事はデータの「前処理」で良く使うPandasのメソッドついての解説です。半分備忘録なので見づらいようでしたらすみません。随時更新しています! 【データの前処理…
その他
ヘルプを確認する。
print ( help ( gspread.Spreadsheet ))
print ( help ( gspread.Spreadsheet.worksheet ))
# ヘルプを確認する
print(help(gspread.Spreadsheet))
print(help(gspread.Spreadsheet.worksheet))
# ヘルプを確認する
print(help(gspread.Spreadsheet))
print(help(gspread.Spreadsheet.worksheet))
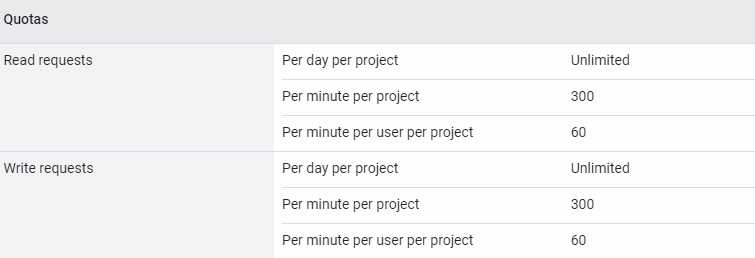
APIリクエストの実行回数制限(Quota)
gspreadはスプレッドシートのSheets APIを利用してスプレッドシートへのアクセスを実現します。ですのでSheets APIの実行回数制限(Quota)について知っておく必要があります。
Sheets APIには下記の実行回数制限があります。
出典:https://developers.google.com/sheets/api/limits?hl=ja データ量が多いスプレッドシートを扱う場合は下記のようにスクリプトの書き方を工夫しましょう。(「Google Apps Scriptの6分の壁」のように。)
APIコールの実行回数制限への対策の例
ループ処理の中で無駄にAPIコールを行わない。 書き込みは、2次元配列に加工してからappend_rowsかvalues_appendで一括で書き込む。 時間がかかる処理は待機時間を挟む。
参考
Google Colab でのgspreadの使い方 Sheets APIのUsage limit gspread docs
まとめ
じょじお
Google ColaboratoryでPythonでスプレッドシートを操作する方法でした。
あわせて読みたい
Pythonでファイル・フォルダ操作【Google Colaboratory】
この記事でわかること! Pythonを使ったファイル操作の基本がわかる。Pythonのos、glob、pathlibの使い方がわかる。Pythonでテキストファイル操作の基本がわかる。 【Py…
あわせて読みたい
【Python】Google ColabでGoogleドライブのExcelを操作をしよう!(OpenPyXL)
この記事でわかること! PythonでExcelを操作するためによく使われるOpenPyXLライブラリの使い方がわかる。Google Colaboratoryを使って無料で簡単にOpenPyXLを実行して…
あわせて読みたい
【Google colab】GoogleドライブのファイルをPythonで操作する。
Google colaboratoryでGoogleドライブのファイルを操作してみます。 この記事でわかること! Google colaboratoryでローカルPCのファイルを操作する方法がわかる。Googl…
Pythonおすすめの講座
デイトラPythonコースのメリット
SNS(インスタ・Twitter・Youtube等)のAPIを駆使したマーケ特化のモダンなシステムを作りながら学べる。 機械学習の基礎を実用的なシステムを作りながら学べる。 現役エンジニアがメンター。1年間Slackで質問し放題。 SlackやTwitterで受講生の発信が盛んなのでひとりでの学習でもモチベ維持しやすい。 月に2~4回行われるオンラインセミナー(現役のマーケター・フリーランサー・デザイナー社長・エンジニア等のWeb界隈のすごい人達が講師)が無料で受講可能。 先着1000名まで1万円引きキャンペーン実施中!(8月31日まで)
\買い切りだからコスパ最高・永久にユーザーコミュニティ参加可能/
Pythonおすすめの本
Pythonおすすめ書籍
¥2,739 (2025/04/25 15:50時点 | Amazon調べ)
ポチップ
▲Python入門者向けの書籍です。デスクワークの業務効率化方面を中心に自動化するスクリプトを作成することができます。Excel・Word・PDF・デスクトップアプリ化・メールなどなど。身近な作業を自動化しながら学べるので事務員の方やエンジニアの方幅広くお勧めできます。
▲Pythonでデータ分析するのに超絶おすすめです。データ分析でよく使うPandasモジュールを中心にデータ加工から分析までの基礎を理解できます。
▲Pythonのお作法なんかが書かれています。



 じょじお
じょじお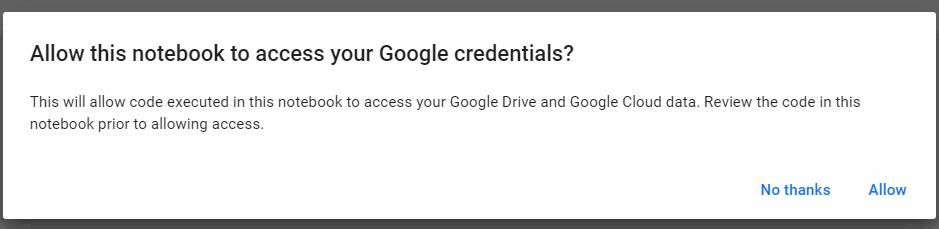
 ぽこがみさま
ぽこがみさま