ガチなシャツ
リライブシャツすごすぎワロタwwwwww【リライブシャツを買ってみたらガチだった。】 リライブシャツ 着るだけで「身体機能をサポートする」怪しいシャツがガチだった。 YouTubeやSNSでバズってた「リライブ...

 じょじお
じょじおWin11に標準搭載されたMicrosoft の無料ツールPADでPDFの表を簡単に抽出できるようになりました。
この記事でわかること!
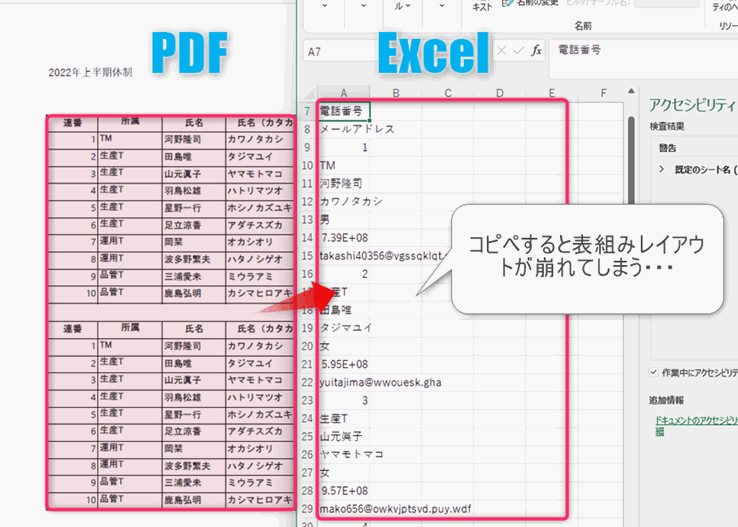
▲PDFの表をExcelにコピペすると、図のようにレイアウトが崩れてしまいます。Windowsユーザなら無料で使用できるMicrosoftのPower Automate for desktop(PAD)ならレイアウトを保持したままExcelに出力できるようになりました。

PDFから表を抽出するには「PDFからテーブルを抽出する」アクションを使います。このアクションは2022年2月に追加された新しいアクションです。
じょじお実際にPDFからテーブルを使ってみました。

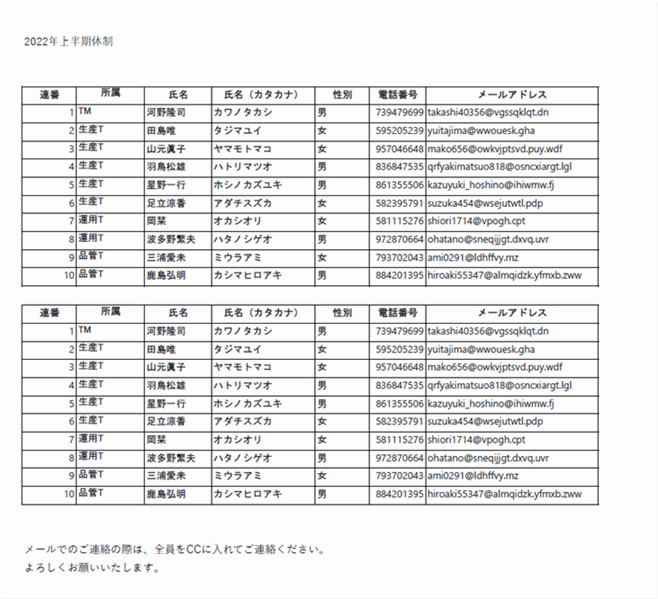
▲今回使用するPDFです。ちょうど、新年度になり関連会社様からチーム体制変更のPDFを頂いたのでそれを模して作りました。中身はプログラムによって自動生成されたダミーデータです。社内ではOutlookの連絡帳やSharepointリストに落とし込みたいのですが、PDFのままではデータ化できないので一旦エクセルにしたいという動機です。
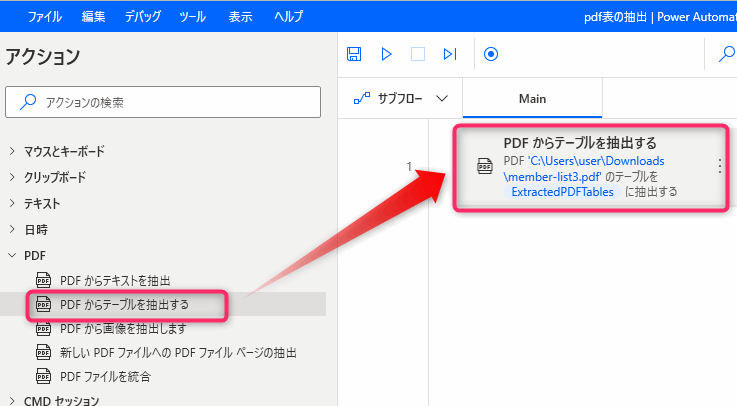
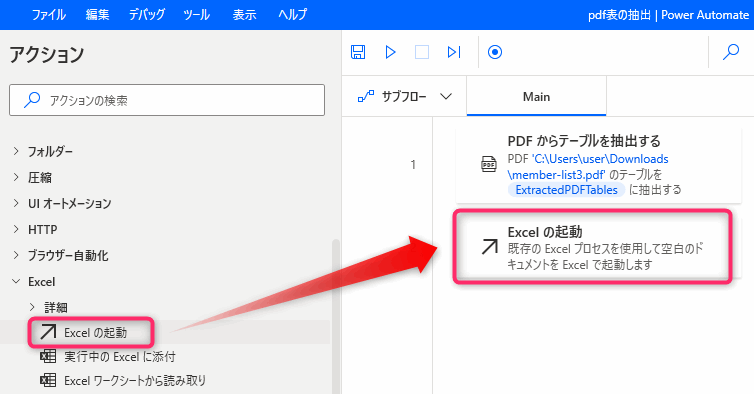
▲「PDFからテーブルを抽出する」アクションはPDFグループにあります。最初にこのアクションを追加します。
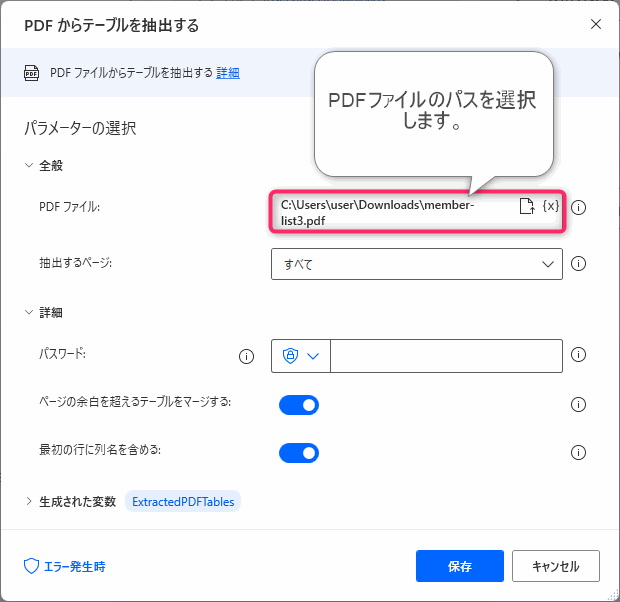
▲パラメータを入力します。一番上の「PDFファイル」にPDFファイルのパスを入力します。
 じょじお
じょじお一回フローを実行してみましょう。フローデザイナー上部の実行ボタンをクリックしてフローを実行します。

▲フローを実行したら「ExtractedPDFTables」変数を確認してみると2つの表を抽出できていることがわかります。これは元PDFデータに表が2つあるからです。PDFによって取得できる表の数は変わります。表のひとつの「詳細表示」をクリックしてみます。
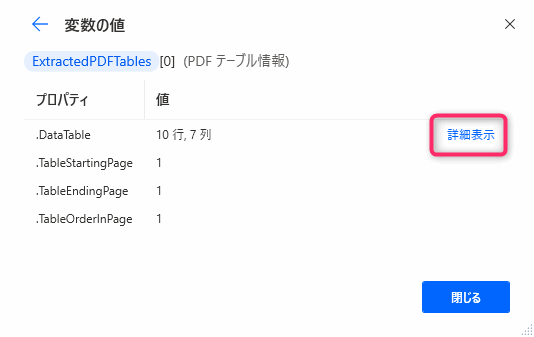
▲Datatableを含むいくつかのプロパティが確認できます。実際の表データはDatatableプロパティに入ってますのでDatatableプロパティの「詳細表示」をクリックして確認してみます。
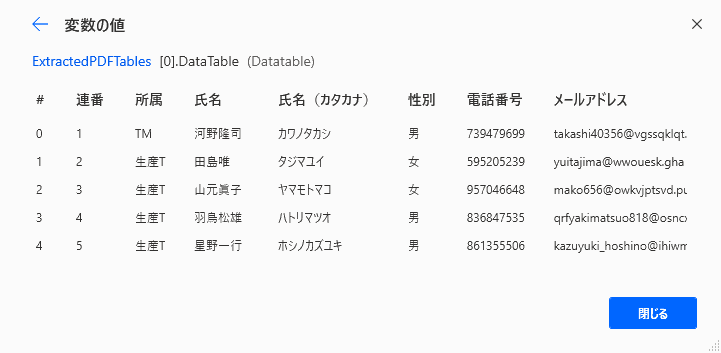
▲Datatableプロパティに表データを確認できました。
じょじおデータを取得できていることがわかりましたら次のステップに進みExcelに書き出す処理を作成していきます。
 ぽこがみさま
ぽこがみさまPDFに表が2つあるためDatatableも2つ作成されました。書き込み処理を2回行う必要があるので、ループの中に書き込み処理を作るとよさそうですね。
 じょじお
じょじお今回は新しいExcelファイルを開いて、1つの表につき1つのExcelシートに書き込もうと思います。
ぽこがみさまなのでまず、表の数だけExcelファイルにシートを用意する処理を作ります。
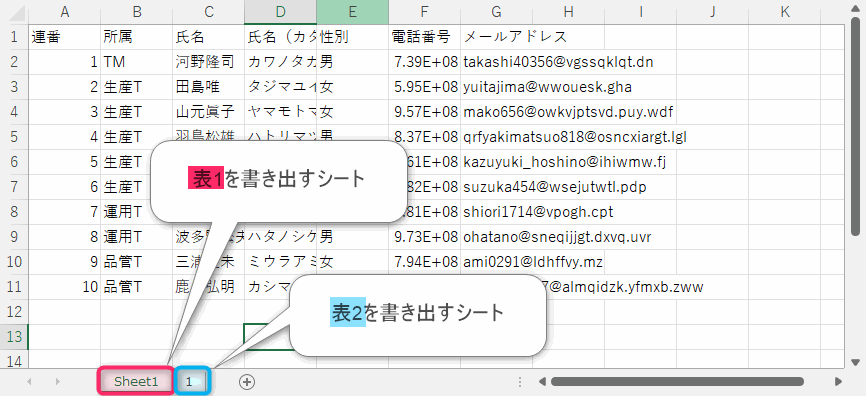
▲出力結果のイメージです。2つ表があるのでシートを2つ追加しています。シートの追加アクションを2回追加してもいいのですが、それだとこのほかのPDFファイルで使えません。他のPDFにも対応できるように、PDFの表の数を自動で読み取って、表の数に合わせてシートを追加するように処理を作っていきます。
じょじおExcelファイルは新しく開くと1枚シートがあります。なのでPDFの表が2個以上の時だけExcelシートを追加するように「IFアクション」を使って表の数を判定します。
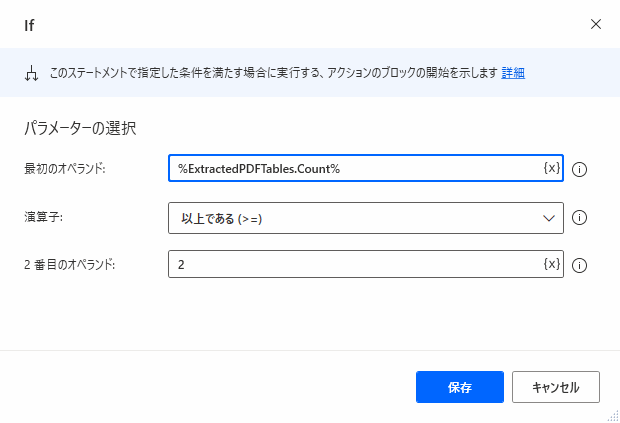
▲パラメータを入力します。表の数は%ExtractedPDFTables.Count%プロパティで確認できます。

▲パラメータの入力ボックステキストボックスところにある{x}をクリックすると
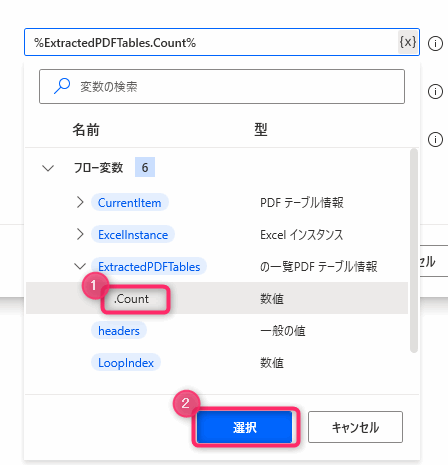
▲変数の一覧が展開するので「ExtractedPDFTables」をクリックし「.count」を選択します。「選択」ボタンをおすと変数を入力できます。
じょじお手入力はタイプミスによるエラーの原因になります。なるべく上記のようにマウス操作で入力しましょう!
ぽこがみさま配列のプロパティなど、手入力でないと入力できないケースもあるのでその場合は手入力します。
じょじおifアクションの中に「Excelにシートを追加する処理」を作っていきます。
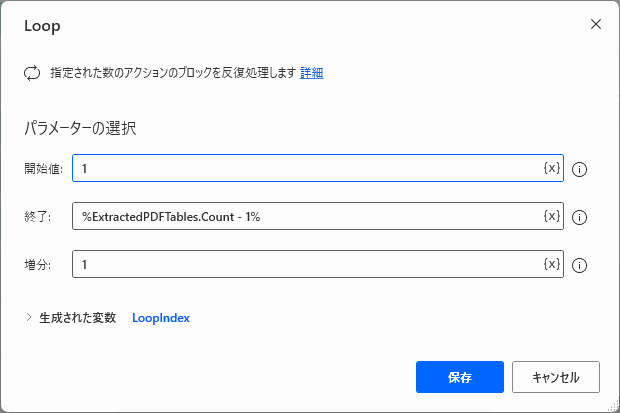
▲パラメータを入力します。
ぽこがみさま「表の数より1少ない回数(%ExtractedPDFTables.Count – 1%)だけ、ループしてくださいねー」という意味です。
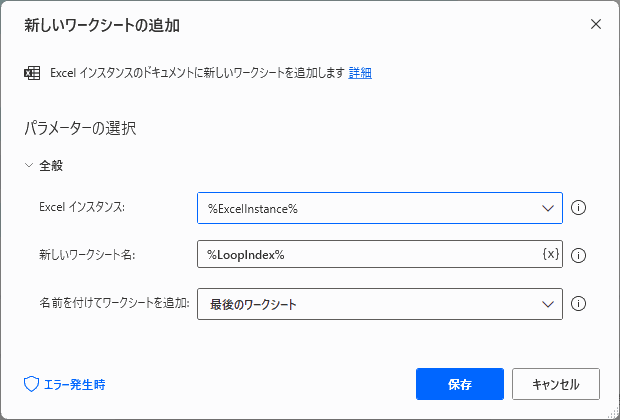
▲パラメータを入力します。
じょじおここからは書き込みの処理を作っています。ExtractedPDFTables変数に格納された表の数だけループしたいので「For each」を使います。
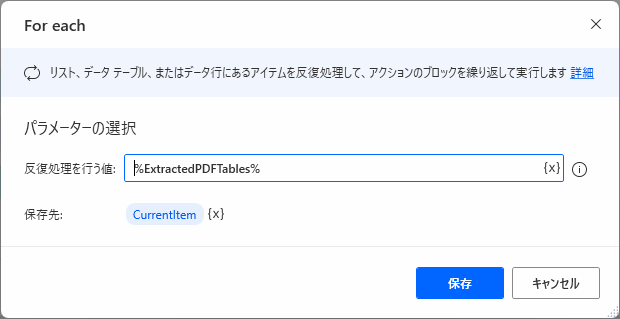
▲パラメータを入力します。
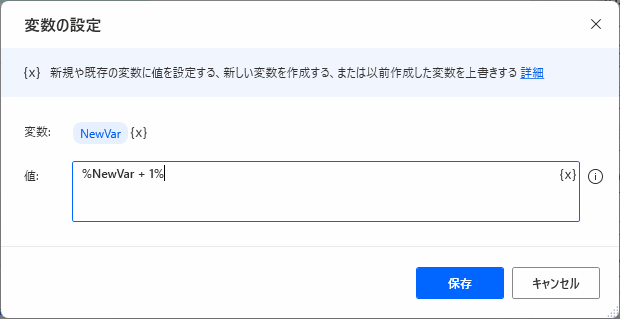
▲パラメータを入力します。この変数は、ループ実行のたびに1ずつ増やすことによって操作シートをコントロールするために使います。(イテレーター)
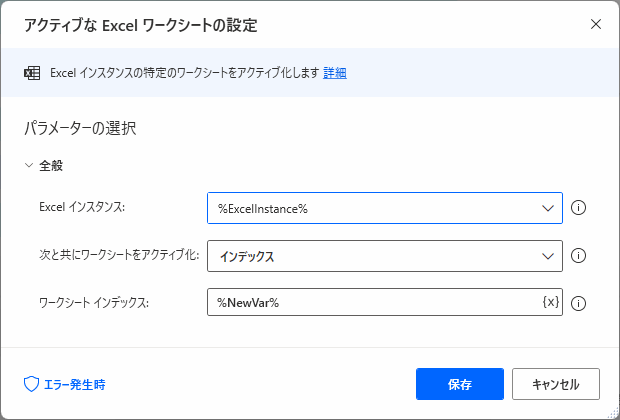
▲パラメータを入力します。
このアクションは、Excelの複数シートの中で今からどのシートを操作するかを設定するためのアクションです。Excelを操作するフローを作るときで、シートが2枚以上あるときは必ず使うかなーと思います。
先程追加した変数NewVarをワークシートインデックスに設定しています。これによって1回目のループ実行時はシート1をターゲットとし、2回目のループ実行時はシート2をターゲットとすることができます。
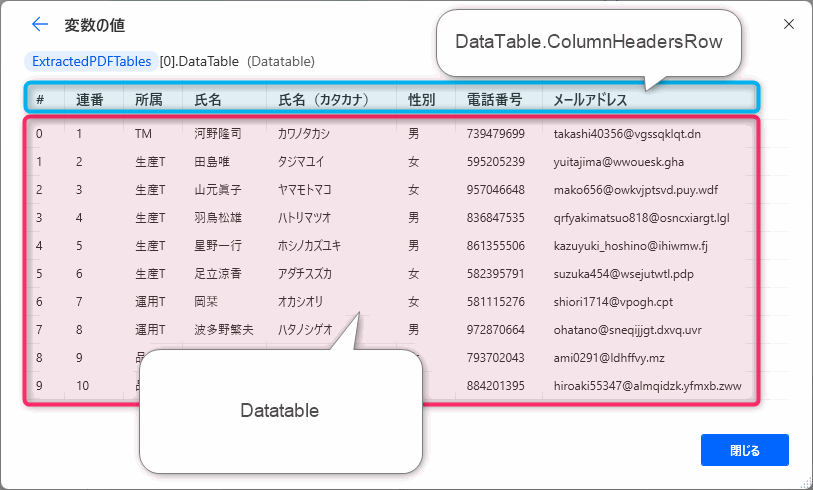
PDFデータは、%ExtractedPDFTables%の中にDatatable型変数として格納されます。Datatable型変数はヘッダー行(列見出し)はデータとヘッダーを別々に保持します。
 じょじお
じょじお上記の両方ともExcelに出力したいので、ここから書き込みアクションを2つ作っていきます。
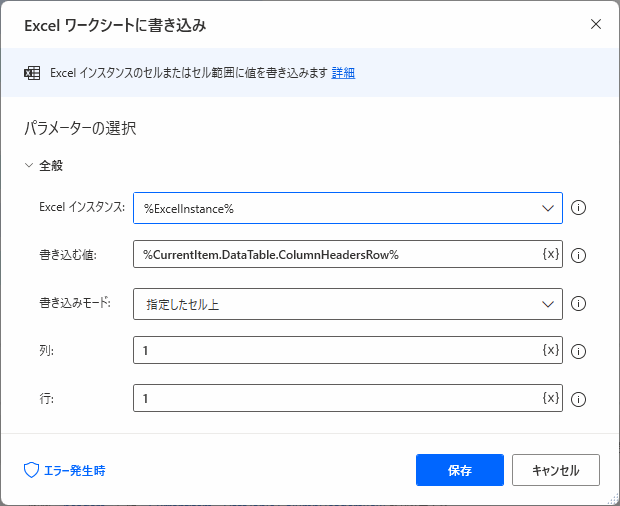
▲パラメータを入力します。1行1列目を基準にヘッダーを書き込みます。
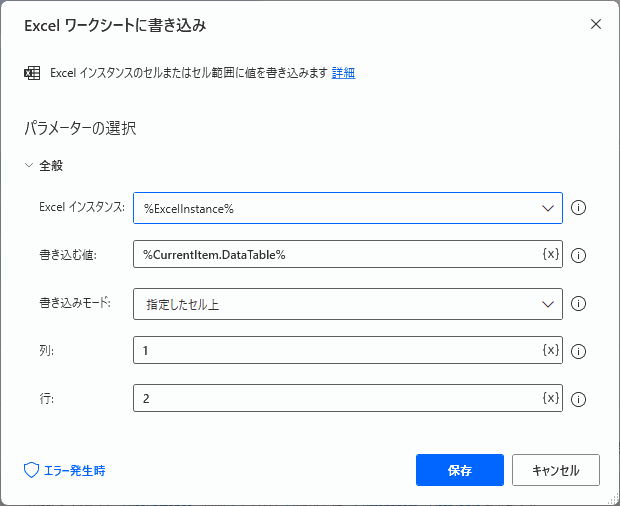
▲パラメータを入力します。表のデータ部分を書き込みます。
▲A2セル(行2列1)からデータを書き込みます。
 じょじお
じょじお以上でフローが完成しました。次のステップでフローを実行してみましょう。
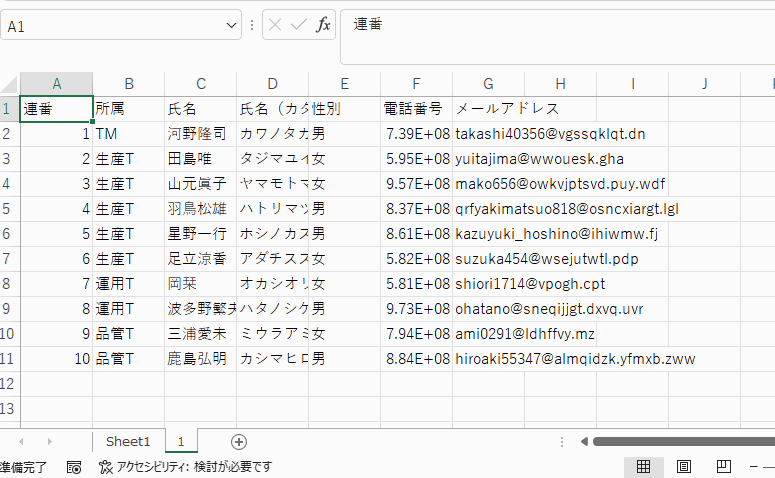
フローを実行すると上の図のようなExcelファイルを出力することができました。
Pdf.ExtractTablesFromPDF.ExtractTables PDFFile: $'''C:\\Users\\user\\Downloads\\member-list.pdf''' MultiPageTables: True SetFirstRowAsHeader: True ExtractedPDFTables=> ExtractedPDFTables
Excel.LaunchExcel.LaunchUnderExistingProcess Visible: True Instance=> ExcelInstance
IF ExtractedPDFTables.Count >= 2 THEN
LOOP LoopIndex FROM 1 TO ExtractedPDFTables.Count - 1 STEP 1
Excel.AddWorksheet Instance: ExcelInstance Name: LoopIndex WorksheetPosition: Excel.WorksheetPosition.Last
END
END
LOOP FOREACH CurrentItem IN ExtractedPDFTables
SET NewVar TO NewVar + 1
Excel.SetActiveWorksheet.ActivateWorksheetByIndex Instance: ExcelInstance Index: NewVar
Excel.WriteToExcel.WriteCell Instance: ExcelInstance Value: CurrentItem.DataTable.ColumnHeadersRow Column: 1 Row: 1
Excel.WriteToExcel.WriteCell Instance: ExcelInstance Value: CurrentItem.DataTable Column: 1 Row: 2
END
# [ControlRepository][PowerAutomateDesktop]
{
"ControlRepositorySymbols": [],
"ImageRepositorySymbol": {
"Name": "imgrepo",
"ImportMetadata": {},
"Repository": "{\r\n \"Folders\": [],\r\n \"Images\": [],\r\n \"Version\": 1\r\n}"
}
}
▲このコードをフローデザイナーにコピペすると今回作成したフローをご自身のPADで再現することができます。
PDFのファイルパスだけをご自身の環境に変更すれば動作します。PDFに表が1個もない場合の例外処理や、Excelを保存して閉じる処理を適宜追加すれば実用的になるかなと思います。
今回作成したフローでは、ループを使ってすべての表をExcelに書き出しました。

▲そうではなく特定の表を指定して操作するには下図のようにインデックス番号を指定します。1個目の表はExtractedPDFTables[0]、2個目の表はExtractedPDFTables[1]に格納されます。インデックスは0から開始するので注意してください。
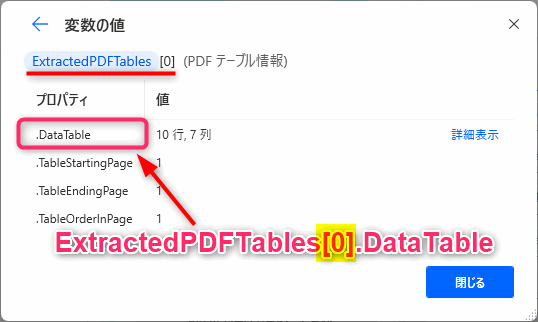
▲1個目の表のデータテーブルはExtractedPDFTables[0].Datatableです。
「PDFからテーブルを抽出する」アクションの仕様や起こりうる例外(エラー)については下記の公式ドキュメントをご確認ください。
Power Automate for desktopには、これ以外にもPDFを扱う便利なアクションがあります。



 じょじお
じょじお以上、Power Automate for desktopで新しく追加された「PDFからテーブルを抽出する」アクションを試してみました!
ぽこがみさまこのブログではRPA・ノーコードツール・VBA/GAS/Pythonを使った業務効率化などについて発信しています。
参考になりましたらブックマーク登録お願いします!

▲Kindleと紙媒体両方提供されています。デスクトップフロー、クラウドフロー両方の解説がある書籍です。解説の割合としてはデスクトップフロー7割・クラウドフロー3割程度の比率となっています。両者の概要をざっくり理解するのにオススメです。

▲Power Automate for Desktopの基本をしっかり学習するのにオススメです。この本の一番のメリットはデモWebシステム・デモ業務アプリを実際に使ってハンズオン形式で学習できる点です。本と同じシステム・アプリを使って学習できるので、本と自分の環境の違いによる「よく分からないエラー」で無駄に躓いて挫折してしまう可能性が低いです。この点でPower Automate for desktopの一冊目のテキストとしてオススメします。著者は日本屈指のRPAエンジニア集団である『ロボ研』さんです。

▲Power Automate クラウドフローの入門書です。初心者の方には図解も多く一番わかりやすいかと個人的に思っています。
Microsoft 365/ Power Automate / Power Platform / Google Apps Script…
▲Udemyで数少ないPower Automateクラウドフローを主題にした講座です。セール時は90%OFF(1200円~2000円弱)の価格になります。頻繁にセールを実施しているので絶対にセール時に購入してくださいね。満足がいかなければ返金保証制度がありますので安心してご購入いただけます。
